Bash: Zeichen aus Zeichenkette (String) entfernen, erstes und letztes Zeichen löschen
Ich habe gerade an einem Linux-Skript getüftelt und habe eine Zeichenkette in die Einzelteile aufspalten lassen. Lästig dabei war nur, dass die von mir gewünschte Zeichenkette auch einen Doppelpunkt am Ende haben kann.
Hinweis: Manche dieser Befehle funktionieren ausschließlich mit der Bash und bei manchen ist sogar eine bestimmte Version und höher notwendig. Sollte also Komplikationen auftreten, könnte es an der Bash-Version liegen.
Bash: Zeichen aus Zeichenkette entfernen
Zum Beispiel gibt nachfolgender Befehl in meinem Fall mehrere mögliche Resultate zurück. Genau genommen sind das 16 (IP-Adresse erreichbar), From (IP-Adresse nicht erreichbar) und connect: (Netzwerk ist nicht erreichbar oder auf Englisch connect: Network is unreachable)
REPLYI=`/bin/ping -c 1 192.168.1.1 -s 8 | /bin/grep -i from | /usr/bin/awk '{print $1}'`
Nun kommt mir aber der Doppelpunkt am Ende des connect: in die Quere. Wir können den Doppelpunkt allerdings wegoperieren. Dafür verwenden wir sed. Allgemein gesprochen würde man das auf der Kommandozeile so realisieren:
echo "connect:" | /bin/sed 's/://g'
Ich brauche es allerdings in meiner Variable, kann aber den Teil mit sed einfach hinten an meinem Befehl anhängen:
REPLYI=`/bin/ping -c 1 8.8.8.8 -s 8 | /bin/grep -i from | /usr/bin/awk '{print $1}' | /bin/sed 's/://g'`
Bash: Letztes Zeichen aus einem String entfernen
Ist man sich sicher, dass der Doppelpunkt lediglich am Ende der Zeichenkette oder des Strings vorkommt, könnte man diese auch anders behandeln und einfach das letzte Zeichen löschen.
echo ${REPLYI%?}
Ist in meinem Fall ungünstig, da es auch die anderen Ergebnisse beeinflussen würde. Also mögliche Ergebnisse wären dann 1, Fro und connect.
Die letzten drei Zeichen löschen:
echo ${REPLYI::-3}
Bash: Erstes Zeichen aus einem String entfernen
Weil wir gerade dabei sind, entfernen wir auch noch das erste Zeichen aus einem String. Das würde in meinem Fall so aussehen:
echo ${REPLYI:1}
Die ersten drei Zeichen würde man so entfernen:
echo ${REPLYI:3}
Das ist übrigens so ein Fall, der nur mit der Bash funktioniert. Versuche ich es mit einer anderen Shell, bekomme ich so ein Ergebnis:

Bash: Das Test-Skript
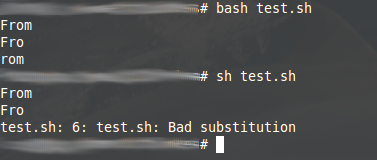
Unterschiedliche Reaktionen
Möchte man haben, dass es mit jeder Shell gleich funktioniert, kommt man wohl um zum Beispiel ein Konstrukt mit einem regulären Ausdruck und sed oder awk nicht herum. Zum Beispiel würde
echo "Hallo" | awk '{print substr($0,2)}'
llo ausgeben. Das hier
echo Hallo | awk '{print substr($0, length($0)-2,3)}'
würde ebenfalls llo ausgeben … wie so oft bei der Kommandozeile führen irgendwie alle Wege nach Rom …















hach ja und täglich grüßt die Stringverarbeitung.
Heute früh muste ich eine csv bearbeiten.
Imprinzip nur eine Kleinigkeit:
- Datensätze von Firmen
- keine Dopplungen
- Jeder Firmenname soll nur einmal vorkommen
- Alles sauber formatieren (trim)
$ sort input.csv | uniq | perl csv.pl > output.csv
hat micht keine 10 min gekostet hätte ich das (wie es eigentlich sein sollte) mit LotusScript umgesetzt hätt ich wohl erheblich länger gebraucht.
Die Linux Shells & Utils sind einfach das beste (auch unter Windows).
MfG Martin
(LotusScript: Scriptsprache für IBM Lotus Notes)