Stable Diffusion auf Ubuntu /Linux Mint – KI-Bilder offline erstellen
Mit GPT4All gibt es bereits einen Chatbot wie ChatGPT, den Du auf Deinem Computer installieren und offline benutzen kannst. Möchtest Du offline Bilder mithilfe einer KI erstellen, dann eignet sich Stable Diffusion hervorragend dafür. Auch diese Software kannst Du offline installieren und nutzen. Vorteilhaft ist ein schneller Computer mit ordentlich Speicher und im Idealfall eine schnelle Grafikkarte. Mein Tuxedo Fusion ist auf jeden Fall schnell genug und hat ausreichend RAM, um binnen weniger Sekunden KI-Bilder mit Stable Diffusion zu erstellen – zumindest reicht es, um damit zu experimentieren.
Ich kann Dir auf jeden Fall eines versprechen. Sobald Stable Diffusion installiert ist, kommst Du Dir vor, wie ein Kind im Süßwarenladen. Die Optionen scheinen endlos und Du kannst auch echt lustige Sachen damit machen – etwa zwei Gesichter mixen und so weiter. Ich erkläre weiter unten, wie das funktioniert.
In diesem Beitrag zeige ich Dir, wie Du sowohl AUTOMATIC1111 als auch EasyDiffusion unter Linux installierst, damit Du Stable Diffusion so einfach und bequem wie möglich nutzen kannst.
Stable Diffusion unter Ubuntu / Linux Mint installieren
Hast Du wie ich eine NVIDIA-Grafikkarte, ist die einfachste Methode, wenn Du Stable Diffusion via AUTOMATIC1111 installierst. Damit kannst Du die KI für Bilder sehr einfach unter Ubuntu installieren. Ich habe das unter Linux Mint 21.2 gemacht, das bekanntlich auf Ubuntu 22.04 LTS basiert.
Zunächst habe ich ein Verzeichnis erstellt und bin dorthin gewechselt:
mkdir stable-diffusion
cd stable-diffusionDu kannst auch einen anderen Namen nehmen. Da Du Dich nun im Verzeichnis befindest, in das Du die KI-Software installieren möchtest, führst Du nachfolgende Befehle aus:
sudo apt install git python3.10-venv -y
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui && cd stable-diffusion-webuiEs muss übrigens auch pip installiert sein. Ist das nicht der Fall, dann gib das Paket oben mit im apt-Befehl an oder installiere es separat:
sudo apt install pipDanach führst Du die Datei webui.sh aus:
./webui.shSollte das nicht funktionieren, musst Du die webui.sh möglicherweise ausführbar machen. Das ist aber nicht schwer. Führe dazu einfach nachfolgenden Befehl aus, wenn Du Dich im gleichen Verzeichnis wie die Datei befindest.
chmod +x webui.shDanach kannst Du das Programm starten und damit setzt Du den Installationsprozess in Gang.
Eine schnelle Internetverbindung ist ratsam. Der Download des Modells mit circa 4 GByte ist groß. Das kann eine Weile dauern.
Auch für den Download anderer Modelle empfiehlt sich eine schnelle Internetverbindung, da die meisten über 2 GByte groß sind.
Installierst Du einige Modelle, kann Stable Diffusion schnell viel Platz fressen. Bei mir waren in kürzester Zeit 21 GByte belegt.
Das Gute an der Sache ist, dass alle Daten in dem von Dir angelegten Verzeichnis bleiben, genauer gesagt in dem Verzeichnis, in dem Du die KI installiert hast. Du kannst also den kompletten Ordner verschieben oder sogar auf einen externen Datenspeicher legen und von dort aus starten. Das funktioniert, ich habe es getestet.
Mit nachfolgendem Befehl startest Du die KI-Oberfläche im Browser, prüfst aber gleichzeitig nach Updates:
./webui.sh --update-checkDas musst Du nicht jedes Mal machen, aber kennen solltest Du den Befehl schon.
Fehler bereinigen: Cannot locate TCMalloc
Auf meinem System hat es beim Start via webui den Fehler oder die Warnung gegeben: Cannot locate TCMalloc (improves CPU memory usage)
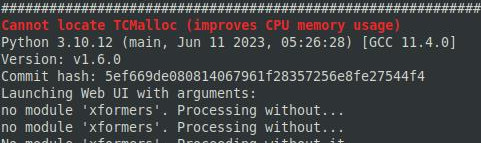
Das Problem lässt sich durch die Installation von Zusatzpaketen bereinigen. Bei mir hat das geholfen:
sudo apt-get install libgoogle-perftools4 libtcmalloc-minimal4 -yDanach konnte ich Stable Diffusion laden und der Fehler war verschwunden.
Software für andere Linux-Distributionen sowie Windows und macOS
Auf der GitHub-Seite von AUTOMATIC1111 findest Du Anleitungen, wie Du die KI-Software auf anderen Linux-Distributionen installierst. Ebenso gibt es zwei Methoden, wie Du das Programm unter Windows zum Laufen bringt. Für macOS stellen die Entwickler ebenfalls eine Anleitung bereit.
Dann findest Du dort noch eine Methode, wie Du die Software komplett manuell installieren kannst. Ich fand die Methode über webui.sh ziemlich angenehm und einfach, wollte aber den manuellen Weg nicht unterschlagen.
Stable Diffusion startet sich selbst
Sobald die Installation abgeschlossen ist, startet das Programm ein Browser-Fenster mit der URL http://127.0.0.1:7861/ – also localhost Port 7861. Auch später startest Du die Software am einfachsten mittels ./webui.sh. Der Prozess für die Installation wird dann übersprungen und das Browser-Fenster startet sich relativ schnell.
Ab sofort kannst Du theoretisch loslegen. Bevor wir nun Bilder und Fotos mit KI erstellen, noch ein paar eher langweilige Hinweise, die ich aber für wichtig halte.
Mit KI Bilder erstellen – die Grenzen erkunden
Bevor wir nun anfangen, mit der KI Bilder und Fotos zu erstellen, wollte ich kurz noch ein Wort zu den Limits verlieren.
Im Screenshot oben siehst Du einen Schieberegler Sampling steps. Fährst Du mit der Maus drüber, bekommst Du eine Erklärung. Damit bestimmst Du, wie oft das erzeugte Bild iterativ verbessert wird. Höhere Werte dauern länger und sehr niedrige Werte können zu schlechten Ergebnissen führen. Allerdings benötigen mehr Schritte auch mehr RAM und das kann Deinen Computer schnell an seine Grenzen bringen.
Auch die Breite und Höhe des Bildes wirkt sich direkt auf den notwendigen Speicher aus. Am besten experimentierst Du mit diesen Parametern und Du bekommst schnell ein Gefühl dafür, was Du Deinem Computer zumuten kannst und was nicht.
Prompts – erstellen wir einige Bilder mit Stable Diffusion
Die sogenannten Prompts sind mit der wichtigste Punkt beim Erstellen von Bildern mit der KI. Hier gibst Du an, welche Schlüsselwörter die Software berücksichtigen soll. Du kannst Deine Szene auch beschreiben und das Programm versucht, das Richtige zu tun.
Etwas in das Prompt zu schreiben, ist einfach. Du kannst schließlich Deinen Gedanken freien Lauf lassen. Das Problem ist, das Richtige in das Prompt zu schreiben. Generell ist es eine gute Idee, sich mehr Bilder generieren zu lassen und dann wählst Du das aus, das am besten passt.
Nach dem Start
Nach dem Start der Software landest Du per Standard im Reiter txt2img. Hier kannst Du eingeben, was Deine Bilder enthalten soll (Prompt) und Du darfst aber auch hinterlegen, was es nicht enthalten soll (Negative prompt). Hier ist Kreativität und Experimentieren gefragt.
Bist Du komplett neu in diesem Bereich, bist Du möglicherweise im Reiter img2img besser aufgehoben. Hier kannst Du ein Bild laden und danach klickst Du auf Interrogate CLIP oder Interrogate DeepBooru. Ich habe festgestellt, dass ersteres mehr ganze Sätze auswirft und letzteres mehr Stichwörter.
Klickst Du erstmalig auf Interrogate Clip, dauert das eine Weile. Hier lädt die Software knapp unter 1 GByte an Daten herunter, damit es Dein Bild analysieren kann.
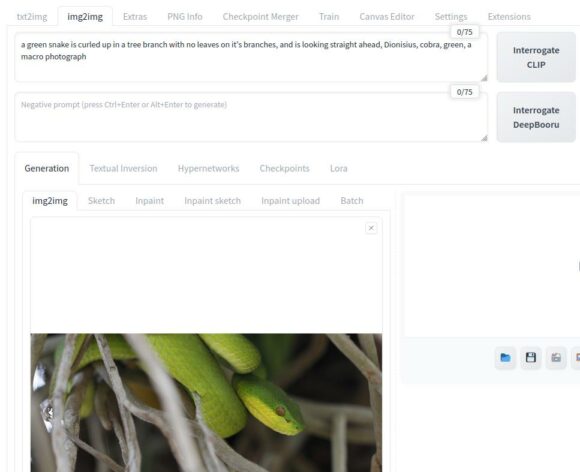
Die Software hat Folgendes als Prompt ermittelt: a green snake is curled up in a tree branch with no leaves on it’s branches, and is looking straight ahead, Dionisius, cobra, green, a macro photograph
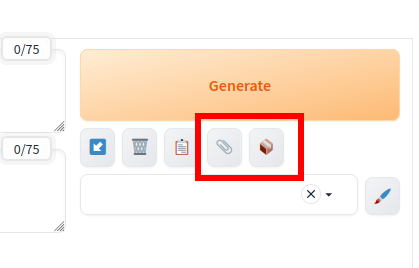
Hinweis: In neueren Versionen von Stable Diffusion sind Interrogate CLIP und Interrogate DeepBooru als Symbole unter die Schaltfläche Generate gewandert.
Du kannst also durch ähnliche Fotos und Bilder lernen, wie die KI Fotos interpretiert. Danach passt Du Dein Prompt an Deine Anforderungen an. Lasse ich das Prompt wie von der KI ermittelt und klicke einfach auf Generate, kommt zum Beispiel so ein Bild heraus:

… gar nicht so schlecht, oder?
Prompts selbst schreiben
Es klingt ziemlich einfach, einer KI wie Stable Diffusion mitzuteilen, was Du haben möchtest. Im Gehirn hast Du sicher eine klare Vorstellung davon. Die Schwierigkeit ist, die Gedanken so in Worte zu wandeln, dass die Software damit optimal klarkommt.
Prompts schreiben ist wohl eine Wissenschaft für sich oder entwickelt sich gerade zu einer. Für den Anfang würde ich die Prompts oder Aufforderungen kurz halten. Knackige, präzise Stichwörter und keine ganzen Sätze. Vielleicht fängst Du mit den wichtigsten an und verfeinerst Deine Anweisung allmählich.
Als Grundregeln für gute Prompts kannst Du Dir merken: Detailliert und aussagekräftige Schlüsselwörter. Du kannst auch angeben, ob es sich um ein Foto, eine Illustration und so weiter handeln soll. Du darfst auch berühmte Künstler im Prompt aufnehmen, an denen sich Dein Bild orientieren soll und so weiter. Sei kreativ. Du trennst die verschiedenen Aspekte Deines Wunschbildes mit Kommas.
Prompt-Beispiel
Prompt: a cat on a street – da kommt vielleicht ein solches Bild heraus.

Das wollte ich so nicht, aber da kann SD nix dafür. Das Programm hat gemacht, worum ich es gebeten habe.
Nun habe ich das Prompt angepasst:
- Prompt: cobblestone street, old town, marketplace, ginger cat sitting next to fountain
- Negative Prompt: disfigured, ugly, cartoon, painting
Das gefällt mir dann schon besser:

Du siehst also, dass Du Stable Diffusion mitteilen musst, was Du möchtest. Viel mit Prompts experimentieren hilft Dir, ein Gefühl dafür zu bekommen.
Wie Du siehst, habe ich auch die Option Negative Prompt benutzt. Damit teile ich dem Programm mit, was das Bild nicht enthalten soll – ich kann damit also bestimmte Sachen ausschließen.
Modelle / Models
Unterschiedliche Modelle produzieren verschiedene Ergebnisse. Es macht aber tierisch Spaß, mit den verschiedenen Modellen zu experimentieren, auch wenn die Downloads groß und mit einer langsamen Internetverbindung zäh sind. Zum Glück musst Du das jeweilige Modell nur einmal herunterladen.
Mit den verschiedenen Modellen für Stable Diffusion kannst Du den Stil bestimmen, der Deine Bilder generiert. Es gibt Modelle, die Bilder möglichst real aussehen lassen. Andere wiederum konzentrieren sich darauf, dem Bild einen Cartoon-Charakter zu spendieren. Wieder andere lassen Dein Bild wie ein Aquarell aussehen und so weiter.
Es gibt neue Modelle am laufenden Band und auch schon jede Menge davon. Daher ist es etwas herausfordernd, das richtige Modell zu finden. An dieser Stelle musst Du etwas experimentieren. Filtere ich bei Huggingface nach Safetensors und Text to Image bekomme ich derzeit fast 5000 Modelle, die ich nutzen könnte.
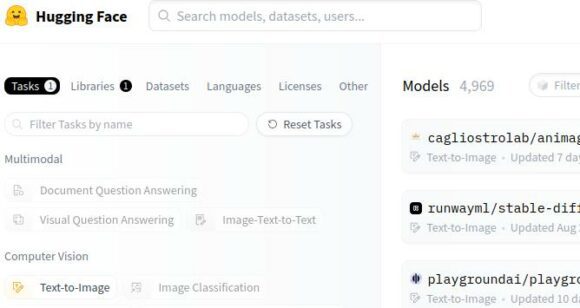
Auf Huggingface.co findest Du eine riesige Auswahl an Modellen für Stable Diffusion. Lies Dir am besten die Beschreibungen der einzelnen Modelle durch und entscheide Dich dann. Bei einigen Modellen ist auch angegeben, dass sie mitunter etwas horny sein können. Das führt eventuell dazu, dass die Bilder etwas mehr sexy werden. Das solltest Du im Hinterkopf behalten, wenn Du Bilder mit KI erstellst.
Models in Stable Diffusion installieren
Neue oder verschiedene Modelle kannst Du ziemlich einfach in Stable Diffusion installieren. Lade einfach ein Modell von der oben genannten Website herunter und verschiebe es in das entsprechende Verzeichnis: <SD-Verzeichnis>/stable-diffusion-webui/models/Stable-diffusion.
Bei mir unter Linux ist das folgende Verzeichnis: /home/bitblokes/stable-diffusion/stable-diffusion-webui/models/Stable-diffusion
Du kannst die installierten Modelle links oben auswählen. Damit ein neues Modell zur Verfügung steht, musst Du die Software neu starten.
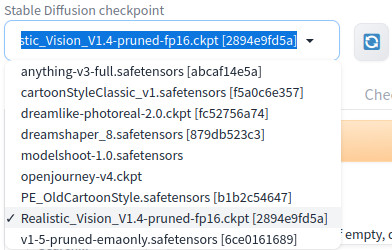
Es ist wirklich interessant, mit den verschiedenen Modellen zu spielen und die verschiedenen Resultate zu sehen.
Unterschied zwischen ckpt und safetensors
In den Modell-Dateien werden von einem maschinellen Lernmodell gelernten Informationen gespeichert. Schließlich muss die Software ihre Informationen irgendwoher beziehen. Es gibt zwei Arten von Modell-Dateien: .ckpt und .safetensor. Die Informationen in diesen Dateien sind gleich. Allerdings gelten .safetensor-Dateien als sicherer, weil sie das Pickle-Modul nicht verwenden.
Das Pickle-Modul in .ckpt-Dateien lässt sich von böswilligen Akteuren ausnutzen, um beliebigen Code auszuführen. Das kann Deinem Computer schaden, es lassen sich Daten stehlen und so weiter. Ich brauche Dir nicht zu erklären, was passieren kann, wenn jemand anderes beliebigen Code auf Deinem Computer ausführen kann.
Du solltest beim Einsatz von .ckpt-Dateien also vorsichtig sein und sie nur aus vertrauenswürdigen Quellen beziehen. Generell solltest Du niemals Daten aus einer dubiosen Quelle einsetzen, weil sie möglicherweise manipuliert wurden.
Die beiden Modell-Formate enthalten also identische Datensätze, um damit Bilder zu erzeugen. Das Format .safetensor hat allerdings weniger Schwachstellen als .ckpt-Dateien.
Wo landen meine generierten Bilder?
In den Einstellungen darfst Du konfigurieren, wo Deine Bilder landen. Per Standard ist das im SD-Verzeichnis unter stable-diffusion-webui/outputs. Bei mir sieht der komplette Pfad für die Ausgabe der Bilder also wie folgt aus: /home/bitblokes/stable-diffusion/stable-diffusion-webui/outputs
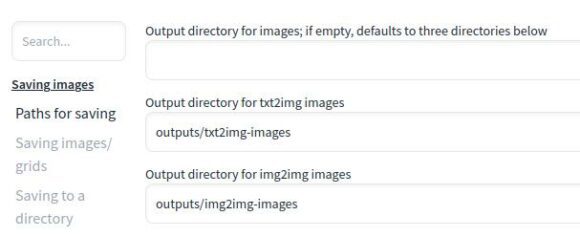
Die Einstellungen bieten Dir aber noch viele andere Optionen. Du kannst etwa das Ausgabe-Format konfigurieren, das per Standard PNG ist. Sieh Dich in den Einstellungen einfach etwas um und passe das Programm an Deine Bedürfnisse an.
Parameter – Seed
Den Parameter Sampling steps habe ich Dir bereits weiter oben erklärt. Jedes Bild, das mit Stable Diffusion erzeugt wird, hat ein einzigartiges Attribut – den Seed. Er repräsentiert die Darstellung eines bestimmten Bildes.
Mit dem Seed eines bestimmten Bildes kannst Du das gleiche Bild wieder erzeugen, wenn Du den Prompt dafür hast. Du kannst einen Seed auch einsetzen, um mehrere Variationen eines Bildes zu erzeugen.
Halten wir fest: Sind Prompt, Seed und Modell identisch, kommt immer das gleiche Bild dabei heraus.
Mit Batch size mehr Bilder erstellen lassen
Ein weiterer interessanter Parameter ist Batch size. Damit kannst Du mehr als ein Bild gleichzeitig erstellen lassen. Ist der Vorgang abgeschlossen, bekommst Du eine Datei mit einem Raster als allen Bildern sowie die einzelnen Bilder.
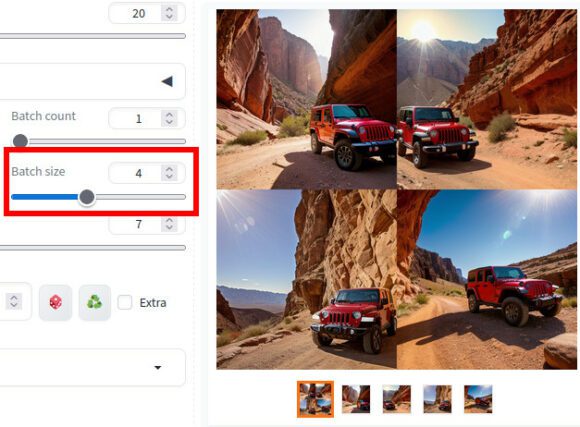
Wie viele Dateien Du gleichzeitig generieren lassen kannst, hängt von Deiner Hardware ab. Versuche ich eine zu hohe Zahl, bekomme ich eine Fehlermeldung, dass nicht genug Speicher zur Verfügung steht.
Nützliche Erweiterung für Stable Diffusion
Unter Extensions kannst Du bei AUTOMATIC1111 Erweiterungen installieren. Einige davon finde ich ziemlich nützlich, zumindest für meine Anforderungen.
Öffnest Du Extensions > Available und klickst dann auf Load from: bekommst Du eine Auswahl an Erweiterungen, die Du mit einem Klick installieren kannst. Du darfst auch Filter setzen, damit Du die Auswahl der entsprechenden Erweiterungen einschränkst. Damit ist es möglich, dass Du gezielter suchst.
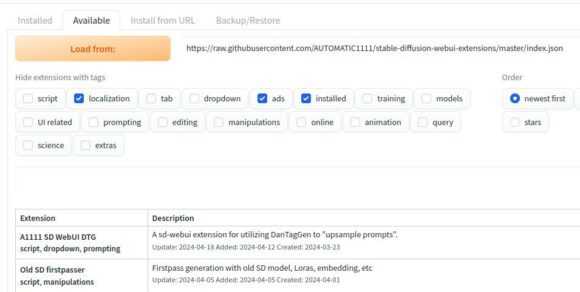
Du kannst auch nach den neuesten Erweiterungen filtern oder nach solchen mit den meisten Stern-Bewertungen und so weiter.
Die Liste ist ziemlich umfangreich, daher kannst es eine Weile dauern, bist Du alle gesichtet hast.
Canvas Editor
Der Canvas-Editor ist eine benutzerdefinierte Erweiterung für AUTOMATIC1111. Damit kannst Layer, Text, Bilder, Elemente und so weiter, um dann Bilder an img2img/inpaint zu senden oder von dort zu empfangen oder Bilder an ContronNet zu senden.
So installierst Du den Canvas Editor:
- Öffne Extensions > Install from URL
- Füge diesen Link ein: https://github.com/jtydhr88/sd-canvas-editor
- Klicke auf Install
- Öffne Installed und klicke auf Appl and restart UI.
Erzeugst Du nun ein Bild, kannst Du es zum Canvas Editor schicken. Dafür gibt es eine entsprechende Schaltfläche.
Schickst Du ein Bild zum Canvas Editor, stehen Dir etliche Möglichkeiten zur Verfügung. Du kannst Dein Bild mit Schrift verzieren, Elemente hinzufügen und so weiter. Deiner Kreativität sind hier kaum Grenzen gesetzt.
Bist Du mit dem Ergebnis zufrieden, kannst Du das Bild herunterladen oder auch wieder zu img2img sowie zu ControlNet schicken.
Der Canvas Editor ist eine sehr umfangreiche Erweiterung, aber wohl gerade für Leute ziemlich nützlich, die Bilder beschriften möchten und so weiter. Du wirst damit wohl etwas spielen und experimentieren müssen, um das volle Potenzial ausschöpfen zu können. Die Lernkurve ist nicht sehr hoch, finde ich, aber die Erweiterung bietet einfach so viele Optionen.
Inpaint background – Bilder schnell freistellen
Eine weitere tolle Erweiterung für AUTOMATIC1111 ist Inpaint background. Damit bekommst Du im Reiter img2img eine neue Option, die sich wenig überraschend Inpaint background nennt. hinzufügt. Die Erweiterung stellt mithilfe von rembg Bilder frei, erzeugt also eine Hintergrund-Maske. Du kannst rembg auch als Einzelanwendung nutzen, dann aber nur via Kommandozeile.
Sobald Du ein Bild an der dafür vorgesehene Stelle ablegst, stellt es das Programm automatisch frei. Das ist sehr benutzerfreundlich.
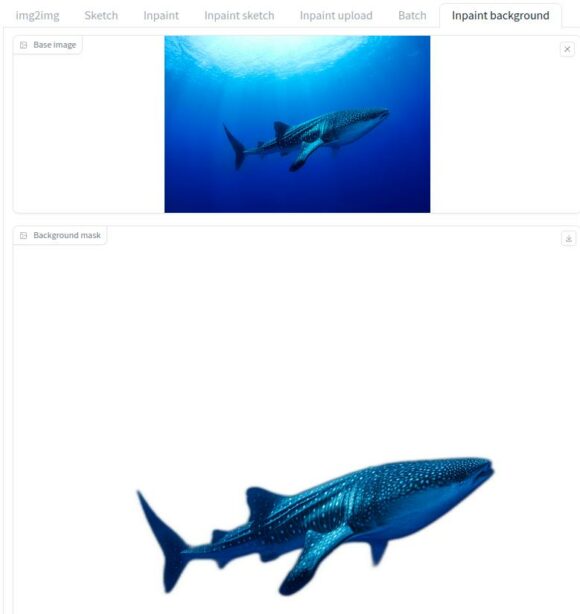
Du bekommst zudem einige neue Optionen, mit denen Du spielen kannst. Damit kannst Du das Modell für die Hintergrunderkennung auswählen und die Alphamattierung konfigurieren.
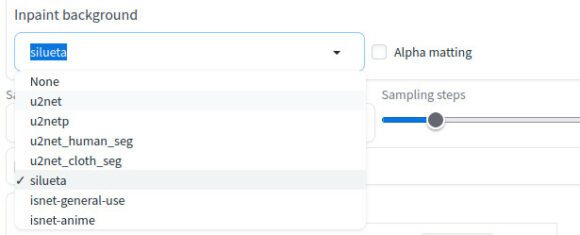
Bist Du Fotograf oder spielst gerne mit Fotomontagen, dann ist diese Erweiterung ein Segen. Ohne viel Aufwand kannst Du Bilder blitzschnell freistellen. Willst Du allerdings nur Bilder freistellen, dann ist dafür die Installation von Stable Diffusion möglicherweise etwas übertrieben. In diesem Fall ist womöglich der Einsatz von rembg via Kommandozeile der bessere Weg.
Was ist ControlNet?
ControlNet ist ein neuronales Netzmodell zur Steuerung von Stable-Diffusion-Modellen. Es ist möglich, ControlNet zusammen mit allen Stable-Diffusion-Modellen zu verwenden.
Die einfachste Form, um SD-Modelle zu benutzen, ist Text-to-Image. Der von Dir eingegebene Text wird dabei als Konditionierung benutzt, um das Bild zu erzeugen. Du schaffst damit also Bilder, die sich an Deiner Textaufforderung orientieren – Du steuerst das Bild also.
ControlNet fügt zusätzlich zur Textaufforderung eine weitere Konditionierung hinzu. Allerdings sind die Möglichkeiten hier riesig.
Möchtest Du weiter in das Thema ControlNet einsteigen und benutzt AUTOMATIC1111, dann empfehle ich Dir die WebUI-Erweiterung dafür. Du findest sie auf GitHub, inklusive einer Installationsanleitung, einer Einführung und einem Link zur technischen Dokumentation.
Bilder mithilfe von KI skalieren
Suchst Du lediglich ein Tool, womit Du Bilder skalieren oder vergrößern kannst, dann ist die Installation von Stable Diffusion vielleicht etwas über das Ziel hinaus geschossen. Mit dem kostenlosen Tool Upscayl kannst Du Bilder mittels KI vergrößern. Die Ergebnisse sind erstaunlich.
Nur die Spitze des Eisbergs
Was ich Dir in diesem Artikel vorgestellt habe, war nur die absolute Spitze des Eisbergs. Es gibt etliche Modelle, mit denen Du experimentieren kannst. Dennoch hoffe ich, dass Dir diese Einführung in Stable Diffusion gefallen hat.
Dann bietet die Software so viele verschiedene Parameter und Optionen – ich bin ehrlich gesagt selbst noch beim Experimentieren, was so manche Funktion eigentlich macht.
Der Kniff ist, die richtigen Prompts zu finden. Das ist eine Wissenschaft für sich. Die Software hilft Dir aber, indem Du ähnliche Bilder lädst und sie von der KI abfragen lässt. Da kommt zwar auch manchmal Quatsch raus, aber die Lernkurve wird dadurch etwas flacher. Du erfährst dadurch, wie die KI das Bild sieht und kannst daraus möglicherweise eigenen Prompts ableiten.
Spannend finde ich die Sache auf jeden Fall und es macht auch irre Spaß, mit Stable Diffusion zu experimentieren. Manche Ergebnisse sind einfach komisch, andere wiederum verblüffend. Hast Du selbst einen schnellen Rechner mit einer NVIDIA-GPU, dann schau Dir AUTOMATIC1111 einfach an. Das kostet nichts, bis auf etwas Zeit.
Stable Diffusion auf einem Raspberry Pi
Ich bin kürzlich über das Projekt OnnxStream gestolpert, womit Du Stable Diffusion auf einem Raspberry Pi Zero 2 installieren und ausführen kannst.
Das funktioniert wohl, aber Du musst eine ordentliche Portion Geduld mitbringen. Was auf einem ordentlich schnellen PC nur wenigen Sekunden dauert, kann auf dem Raspberry Pi Zero 2 mehrere Stunden in Anspruch nehmen.
Ich wollte es nur erwähnt haben, dass es auch Anstrengungen gibt, KI auf schwächeren Geräten zu betreiben. Ob das Spaß macht, steht auf einem anderen Blatt.
Easy Diffusion – einfache Alternative für Stable Diffusion
Das Team von Easy Diffusion behauptet, dass es die einfachste Art ist, Stable Diffusion auf Deinem Computer zu installieren und zu benutzen.
Es ist tatsächlich ziemlich einfach, Easy Diffusion zu installieren. Lade einfach die entsprechenden Dateien für Linux, macOS oder Windows herunter. Du bekommst eine .zip-Datei, die Du auspackst. Wechsle anschließend in den Ordner easy-diffusion und für die entsprechende Datei aus. Unter Linux ist das ./start.sh bei mir. Damit stößt Du die Installation an und das Script erledigt alle Arbeiten und Downloads für mich.
Im Anschluss öffnet sich die Benutzeroberfläche im Browser und Du kannst sofort loslegen. Die WebUI-Oberfläche wirkt tatsächlich etwas benutzerfreundlicher als bei AUTOMATIC1111. Du kannst sofort mit einem Prompt loslegen und Dir ein Bild erstellen lassen, indem Du auf Make Image klickst.
Fährst Du nach der Erstellung des Bildes mit der Maus darüber, bietet Dir EasyDiffusion einige Optionen an. Du kannst mit nur einem Klick ähnliche Bilder erstellen, das Bild vergrößern und so weiter. Auch an dieser Stelle ist ED ziemlich benutzerfreundlich.
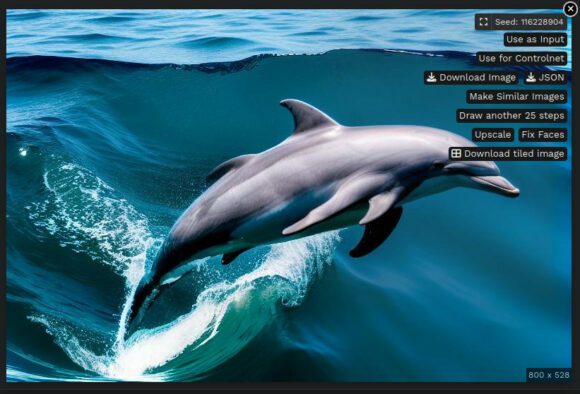
So sehr ich die umfassenden Möglichkeiten und Optionen von AUTOMATIC1111 schätze – EasyDiffusion eignet sich wohl besser für Leute, die einen möglichst einfachen Einstieg möchten.
Hinweis: Im Gegensatz zu AUTOMATIC1111 speichert EasyDiffusion Deine Bilder nicht automatisch. Möchtest Du das, musst Du es in den Einstellungen aktivieren.
EasyDiffusion mit Unterstützung für ControlNet
Ebenfalls toll ist, dass die aktuelle Version von EasyDiffusion bereits komplette Unterstützung für ControlNet mit sich bringt. Die gängigen ControlNet-Modelle sind nativ integriert. Du wählst einfach ein Bild für ControlNet aus, wählst danach den entsprechenden Filter oder das ControlNet-Modell und führst es aus. Eine zusätzliche Konfiguration oder manuelle Downloads sind nicht notwendig. Die Software lädt die notwendigen Modelle bei der erstmaligen Nutzung automatisch herunter. Das Programm unterstützt auch benutzerdefinierte ControlNets.
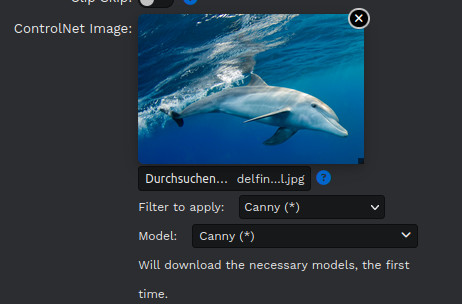
Der Einsatz von ControlNet ist mit EasyDiffusion tatsächlich sehr viel einfacher und benutzerfreundlicher als mit AUTOMATIC1111.
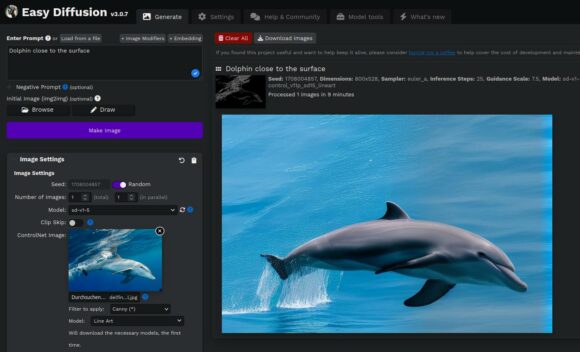
Es ist schon beeindruckend, welchen Unterschied ControlNet machen kann.
Verknüpfungen zu den Modellen
Tipp zu den Modellen: Damit die Modelle für SD und ED nicht doppelt so viel Speicherplatz benutzen, habe ich einfach Verknüpfungen unter Linux angelegt. Das funktioniert entweder über die Kommandozeile mit ln -s (symbolischer Link) oder manche Dateimanager bieten die Option auch an, etwa Nemo.
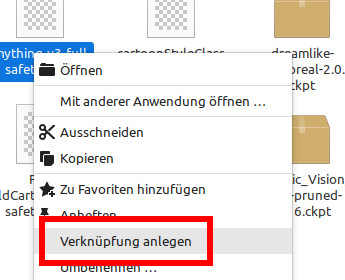
Dieser kleine Trick spart mir mehrere GByte an Platz. Das funktioniert auch mit den ControlNet-Modellen.
Menschen mixen – so geht das
Du kannst mit Stable Diffusion ziemlich witzige Dinge machen, etwa ein Gesicht aus zwei anderen Gesichtern erstellen. Die Sache ist allerdings, dass das am besten mit Promis funktioniert. Je bekannter die Person, desto mehr Informationen hat das jeweilige Modell wahrscheinlich darüber.
Für AUTOMATIC1111 ist die Syntax wie folgt: [person 1: person2: faktor] – Du gibst also zwei Personen an und mit dem Faktor bestimmst Du die Gewichtung der ersten Person. Der Faktor ist eine Zahl zwischen 0 und 1. Er gibt den Anteil an der Gesamtzahl der Schritte an, wenn das Stichwort von Person 1 zu Person 2 wechselt. Ist der Faktor also 0.2 und es gibt 20 Schritte, dann wechselt das Programm nach 4 Schritten von Person 1 zu Person 2.
Testen wir das. Prompt: [Arnold Schwarzenegger: Prince Charles: 0.6], DSLR, rim lighting, studio lighting, looking at the camera,

Ja, im Prompt habe ich Prince Charles benutzt, da es darüber im Internet vermutlich mehr Informationen gibt.
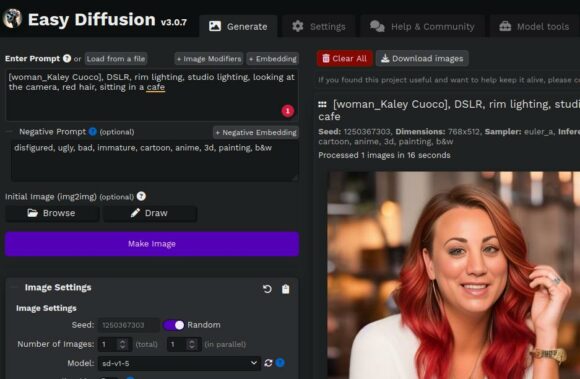
Du kannst auch nur eine Person mixen. Ein Beispiel-Prompt dafür wäre: [woman: Kaley Cuoco: 0.5], DSLR, rim lighting, studio lighting, looking at the camera, red hair, sitting in a cafe

Nun besteht die Hälfte des Bildes aus Penny von The Big Bang Theory. OK, die Augen sind etwas verbesserungswürdig und an dieser Stelle müsste man noch etwas am Prompt feilen. Du kannst aber sehen, was ich damit meine, nur eine Person in das Bild zu mixen.
Natürlich hängt auch hier viel vom Modell ab, das Du einsetzt.
Tipp: Bei EasyDiffusion benutzt Du statt des Doppelpunktes einen Unterstrich als Trennzeichen. Beispiel: [person 1_person 2]
Du siehst also, dass es mit EasyDiffusion ebenso einfach ist, Leute zu mixen.
Stable Diffusion macht Spaß – ist aber überwältigend
Wie bereits erwähnt, macht es ziemlich Spaß, sich mit dem Thema Bilderstellung mit KI zu befassen. Die Ergebnisse sind erstaunlich, lustig, überraschend und so weiter. Du kannst Stunden damit verbringen, ohne dass es langweilig wird.
Das Thema ist aber auch so umfangreich, dass der Einstieg ziemlich frustrierend sein kann. Gerade EasyDiffusion könnte Dir den Einstieg allerdings erleichtern.
Ich hoffe, Dir mit diesem Artikel das Thema KI und Stable Diffusion richtig schmackhaft gemacht zu haben. Viel Spaß beim Installieren und beim Experimentieren mit einer Spielzeugkiste, die scheinbar unendlich viele Möglichkeiten bietet.