PDF OCR funktioniert gut mit ocrmypdf
Eine Bekannte von mir hat ein altes Buch als PDF-Format (Bilder / Scan), das sie benötigt, um eine Arbeit zu schreiben. Das Buch ist auf Deutsch und sie muss Teile davon übersetzen. Dafür benutzt sie DeepL. Das Problem ist aber, dass sie keine Textpassagen kopieren kann, da das Dokument nicht als Text vorliegt. Eine OCR-Software hat geholfen.
Ich habe ihr gesagt, dass wir es durch eine OCR-Software laufen lassen können. Das mag zwar nicht 100 % genau sein, aber sie kann viele gewünschte Textpassagen kopieren und via DeepL übersetzen lassen, damit sie den Sinn versteht. Vorweg: Das hat ihr sehr viel Zeit gespart.
Es gibt hier sicherlich einige Tools, die Du verwenden kannst. Ich habe es mit ocrmypdf gemacht, das tesseract und einige andere freie Tools benutzt. Es ist außerdem in den Repositories von Ubuntu oder Linux Mint zu finden.
ocrmypdf für die Linux-Kommandozeile
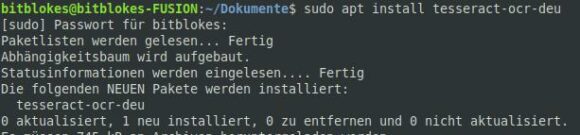
Bevor Du ocrmypdf benutzt, solltest Du zunächst tesseract Deutsch installieren. Das funktionierte bei mir unter Linux mit mit einem einfachen Befehl auf der Kommandozeile:
sudo apt install tesseract-ocr-deuDas Paket ist nicht groß und die Installation dauert nur wenig Zeit.
Möchtest Du weitere Sprachen installieren, findest Du mit nachfolgendem Befehl alle verfügbaren:
apt-cache search tesseract-ocrIm Anschluss installierst Du ocrmypdf. Ich habe das ebenfalls via Kommandozeile gemacht:
sudo apt install ocrmypdfNach der Installation kannst Du das Tool sofort benutzen. Allerdings geht es per Standard von Englisch aus. Hast Du ein deutsches Dokument, gibst Du am besten die Sprache an:
ocrmypdf -l deu input.pdf output.pdfDu kannst übrigens auch mehrere Sprachen benutzen. Als Beispiel Englisch und Deutsch. Dazu verwendest Du den Parameter -l wie folgt:
ocrmypdf -l eng+deu input.pdf output.pdfHast Du mehrere Dokumente, über die Du die OCR-Software laufen lassen möchtest, kannst Du sie als Batch verarbeiten lassen. Du kannst alle PDF-Dokumente in einen Ordner kopieren und führst anschließend den nachfolgenden Befehl aus:
for f in ./*.pdf; do ocrmypdf "$f" "$(basename "$f" ".pdf")_ocr.pdf"; doneFür ocrmypdf gibt es ein umfassenden Online-Handbuch, falls Du weitere Optionen suchst.
PDF in einfaches Textdokument umwandeln
Das Tool pdftotext ist eine weitere Option, um den Text aus einem PDF zu bekommen. Es befindet sich in den Repositories vieler Linux-Distributionen. Es ist Teil der Xpdf-Software. Um das Tool nutzen zu können, habe ich das Pakert poppler-utils installiert:
sudo apt install poppler-utilsDie Syntax ist einfach:
pdftotext Optionen PDF-Datei Text-DateiDas Tool funktioniert aber nur, wenn der Text im PDF klar ist. Im Fall meiner Bekannten hat das Tool keinen sinnvollen (oder nicht viel) Text extrahieren können und ich musste eine OCR-Software benutzen.
pdf2docx benutzen – PDF zu DOCX konvertieren
Das Programm pdf2docx kannst Du via pip installieren. Bei mir hat der Befehl funktioniert:
pip3 install pdf2docxDanach musst Du allerdings ein kleines Python-Programm schreiben, um das gewünschte PDF-Dokument in DOCX zu konvertieren.
from pdf2docx import Converter
pdf_file = '/pfad/zu/PDF'
docx_file = '/pfad/zu/DOCX'
# convert pdf to docx
cv = Converter(pdf_file)
cv.convert(docx_file) # all pages by default
cv.close()Es ist etwas Handarbeit notwendig, aber bei mir hat das funktioniert.
Mit LibreOffice headless
Bei meinen Recherchen habe ich auch gefunden, dass angeblich dieser Befehl funktionieren soll.
libreoffice --invisible --convert-to docx:"MS Word 2007 XML" input.pdfDas hat bei mir nicht funktioniert. Auch andere Leute haben den gleichen Fehler wie ich erhalten: Error: Please verify input parameters … Ich habe eine Lösung gesucht, aber nicht wirklich eine gefunden. Deswegen habe ich das Experiment nach ein paar Minuten abgebrochen.
Ein kurzes Wort zum Parameter –invisible von LO. Damit startet LibreOffice im unsichtbaren Modus. Weder das Startlogo noch das erste Programmfenster erscheinen. Du kannst LO also via Kommandozeile nutzen. Startest Du das Programm mit diesem Parameter, kannst Du es nur mittels kill (Linux / Unix) oder den Taskmanager (Windows) beenden.
Zusatztipp: Mit LibreOffice eine odt-Datei headless via Kommandozeile in ein PDF zu verwandeln, ist allerdings möglich und sogar ziemlich einfach:
libreoffice --headless --convert-to pdf datei.odt